


ATR自然会話音声データベース48k
本データベースは、従来品である「ATR自然発話音声データベースSDB」および「ATR自然発話音声・言語データベースSLDB(日英対話)」に収録された模擬会話タスクを統合し、DAT(Digital Audio Tape)で収録した48kHz原音をリサンプルすることなく、再編集した新構成の高品質自然発話音声データベースです。
本データベース(48kHz)のラインナップにあわせて、従来品「ATR自然発話音声データベースSDB」および「ATR自然発話音声・言語データベースSLDB(日英対話)」に収録されている16kHz版(模擬会話タスク)についても、用途やシステム要件に応じてご選択いただけるよう併せてご提供しております。
実際の話し言葉に見られる言い淀み・言い直し・語尾の変化などを含む自然発話を、極めて静かな環境にて高音質で収録しています。実会話に近い発話の揺らぎを反映しており、対話システムや音声認識モデルの実用性向上に資する基盤的データとして最適です。
また、従来の16kHzでは捉えきれなかった子音の微細な立ち上がりや、語尾の揺れ、息づかい、間といった非言語情報を保持しているため、音素境界の推定精度が向上し、タイムアライメントや誤認識の低減に大きく貢献します。
※一部都合によりリサンプルした音声(9ファイル)を含む
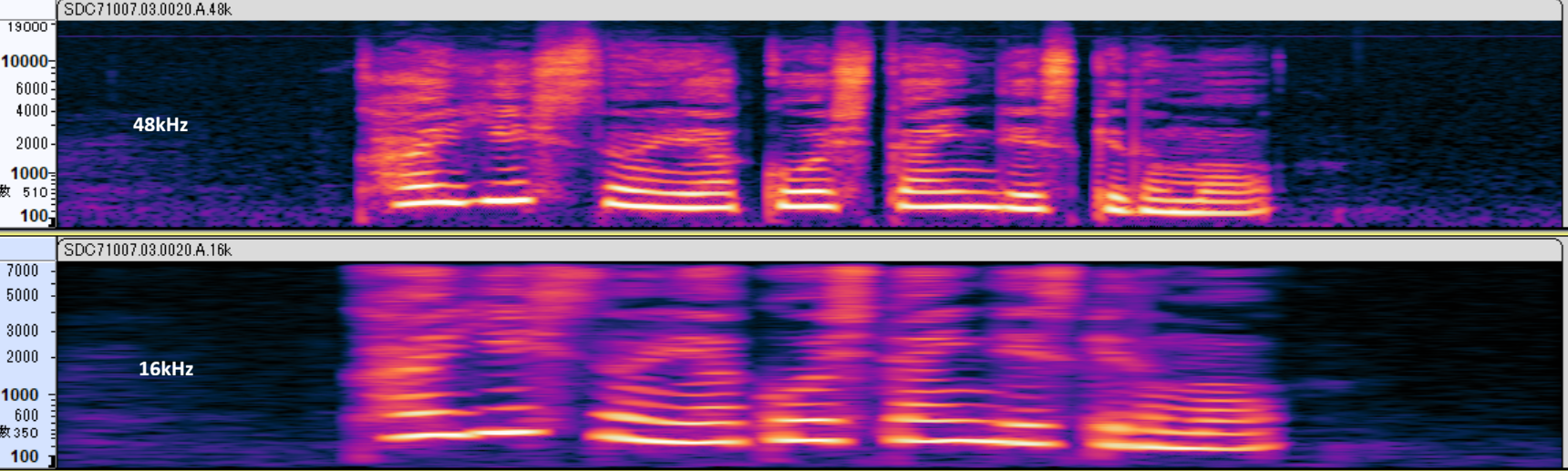
同一ファイルのスペクトログラム比較
上段:48kHz
下段:16kHz
48kHz音声コーパスの特長と用途
●音声合成分野
(1) 48kHz高サンプリング音声で、自然で豊かな表現を実現
近年の音声合成技術の進化に伴い、音質・自然性への要求がますます高まっています。48kHzの高サンプリング音声コーパスを活用することで、より自然で感情豊かな表現が可能となります。
(2) リップシンク精度の向上
CGキャラクターやアニメーションにおいても、滑らかな口形アニメーションとの高精度な同期が可能となり、視覚的な自然性を高めます。
幅広い音声合成用途に対応
本データは、以下のような用途にもご活用いただけます。・ 話者適応型TTSのベースデータ
・ 感情音声データの生成
・ 教育・学習コンテンツ向け音声合成
●音声認識分野
音声認識の精度向上には、現実の話し方を正しく捉えた学習データが不可欠です。本データベースでは、自然な言い淀み・言い直し・フィラー(あの、えー)などを含む会話音声を、極めて静かな環境下で高精細に収録したものです。
(1)高解像度の音声データをそのまま活用
リサンプルを行わない高品質な48kHz音声により、フィルタリングや適切なリサンプリングを用いた高精度な音声認識が実現可能です。
(2)環境音との自然な合成も実現
16kHz音声では難しい、高周波成分を含む環境音との自然な合成が可能です。実際の利用シーンを想定したリアルな音響環境下での認識性能検証にも適しています。
(3) 汎用音声認識エンジンのベースモデルに最適
多様な話者バリエーションを活かし、不特定話者向け音声認識製品やサービスのベースモデル構築に最適です。また、話者識別・話者クラスタリングといった応用タスクにもご利用いただけます。
(4) 認識エラーの傾向分析・弱点の可視化
本コーパスを用いることで、実運用環境における認識エラーの傾向分析や、認識システムの構造的な弱点の可視化が可能となります。これにより、製品の品質向上や改善サイクルの効率化に貢献します。
仕様ピックアップ
| 発話タスク | 旅行に関する模擬会話形式による対話想定発話(非対面収録) |
| 総話者数(男/女別) | 562名(218名/344名) |
| 総発話時間(*1) | 47.28時間 |
| 総発話数 | 38,544発話 |
データ構成
48k音声データ :WAV形式(48kHz,16bit,MONO) サンプル1(男性) サンプル2(女性)ラベルデータ :書き起こし音素列,発話区間時刻 サンプル1
書き起こしデータ:発話文書き起こし サンプル1
形態素データ :書き起こし文を基にした形態素解析結果 サンプル1
収録情報データ :収録要件情報 サンプル1
価格
商用利用 ¥4,000,000 (税抜)
ライセンス区分については、こちらをご覧ください